18.1 Loading Data in PEcAn
If you are loading data in to PEcAn for benchmarking, using the Benchmarking shiny app [provide link?] is recommended.
Data can be loaded manually using the load_data function which in turn requires providing data format information using query.format.vars and the path to the data using query.file.path.
Below is a description of the load_data function an a simple example of loading data manually.
18.1.1 Inputs
Required
data.path: path to the data that is the output of the functionquery.file.path(see example below)format: R list object that is the output of the functionquery.format.vars(see example below)
Optional
start_year = NA:end_year = NA:site = NAvars.used.index=NULL
18.1.2 Output
- R data frame containing the requested variables converted in to PEcAn standard name and units and time steps in
POSIXformat.
18.1.3 Example
The data for this example has already been entered in to the database. To add new data go to new data documentation.
To load the Ameriflux data for the Harvard Forest (US-Ha1) site.
- Create a connection to the BETY database. This can be done using R function
bety = PEcAn.DB::betyConnect(php.config = "pecan/web/config.php")where the complete path to the config.php is specified. See here for an example config.php file.
- Look up the inputs record for the data in BETY.
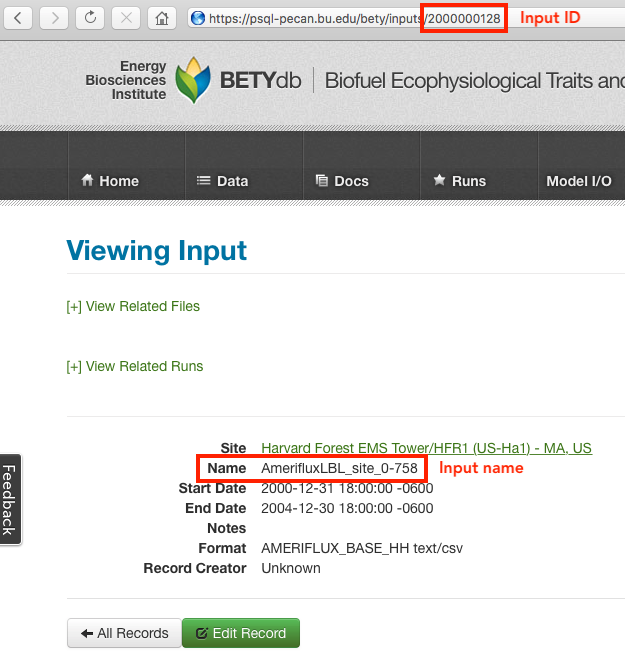
To find the input ID, either look at
The url of the record (see image above)
- In R run
library(dplyr)
input_name = "AmerifluxLBL_site_0-758" #copied directly from online
input.id = tbl(bety,"inputs") %>% filter(name == input_name) %>% pull(id)Additional arguments to
query.format.varsare optional- If you only want to load a subset of dates in the data, specify start and end year, otherwise all data will be loaded.
- If you only want to load a select list of variables from the data, look up their IDs in BETY, otherwise all variables will be loaded.
In R run
format = PEcAn.DB::query.format.vars(bety, input.id)Examine the resulting R list object to make sure it returned the correct information.
The example format contains the following objects:
$file_name
[1] "AMERIFLUX_BASE_HH"
$mimetype
[1] "csv"
$skip
[1] 2
$header
[1] 1
$na.strings
[1] "-9999" "-6999" "9999" "NA"
$time.row
[1] 4
$site
[1] 758
$lat
[1] 42.5378
$lon
[1] -72.1715
$time_zone
[1] "America/New_York"The first 4 rows of the table format$vars looks like this:
| bety_name | variable_id | input_name | input_units | storage_type | column_number | bety_units | mstmip_name | mstmip_units | pecan_name | pecan_units |
|---|---|---|---|---|---|---|---|---|---|---|
| air_pressure | 554 | PA | kPa | 19 | Pa | Psurf | Pa | Psurf | Pa | |
| airT | 86 | TA | celsius | 4 | degrees C | Tair | K | Tair | K | |
| co2atm | 135 | CO2_1 | umol mol-1 | 20 | umol mol-1 | CO2air | micromol mol-1 | CO2air | micromol mol-1 | |
| datetime | 5000000001 | TIMESTAMP_START | ymd_hms | %Y%m%d%H%M | 1 | ymd_hms | NA | NA | datetime | ymd_hms |
- Get the path to the data
data.path = PEcAn.DB::query.file.path(
input.id = input.id,
host_name = PEcAn.remote::fqdn(),
con = bety)- Load the data
data = PEcAn.benchmark::load_data(data.path = data.path, format = format)